Sep 12 2008
Application Performance and The Trap of Object-Orientedness
Pidasin neil päevil Webmedias ettekande antud teemal. Põhimõtteliselt olen sel teemal siin ka varem juttu teinud, aga arendasin teemat natuke edasi.
Originaalslaidid saab leida siit, aga edasi juba sisu ise, koos minu märkmetega, mis on ehk hajusamad/kaootilisemad, kui minu tekst tavaliselt ![]()



The basic tenets of OOP are abstractions, encapsulation, inheritance and polymorphism: Hopefully all of us know about them, and know when and how to use them. The main idea is that we don’t have to know what’s inside a component, we can swap them in and out, and do a bunch of other cool things.
Make no mistake about it, I think OOP is good, it makes us more productive, and it makes our code much more flexible, maintainable and extensible.However, it also has some inherent dangers: we see an API, it looks very safe and simple. We add 1 line of code that is using this API and introduce who knows what. Perhaps it adds 5 extra SQL queries? Or does some processing that doesn’t scale to our data?

Let’s look at a civil engineering analogy.
In civil engineering, there are whole courses and thick handbooks about the properties of different materials. Various grades of steel, stone, wood and so on. Engineers have to know their strength, density, elasticity, how much they expand and contract in heat, all kinds of things
Now imagine using “encapsulated” building blocks. You see the blocks, they are nice and shiny, and the salesman tells you they are super good and strong. But you have no idea what’s inside them, how they are made, how they behave in different kinds of weather or stress. The engineers would rightfully ask: are you crazy or what?
Unfortunately, software engineers are just like that. Application programmers don’t know what’s happening in their class libraries. Class library writers don’t know what’s happening in the operating system. Systems programmers don’t know what’s happening in the hardware. So you have all these layers of software that were created by people who don’t quite know how the other layers behave. It’s kind of a miracle that software ever works at all.
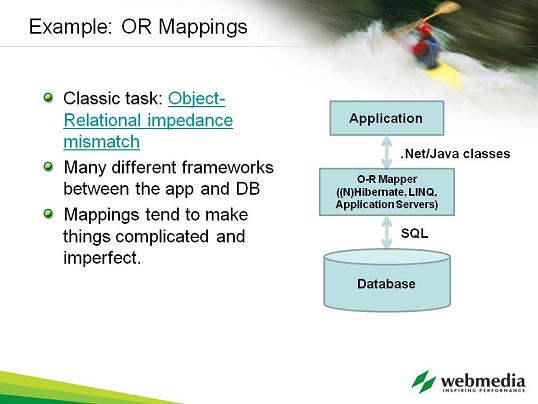
Let’s look at a classic problem. We have a database with a bunch of stuff. It’s very nicely in 3rd normal form.
In the application layer, we want to handle rather different kinds of data, we have the Rich Domain Model, lots of OO classes, objects, subclasses, methods, properties etc.
Many different frameworks have been invented that perform object-relational mapping between the database and the object-oriented classes. For example, here in Webmedia we use Nhibernate and other similar technologies. So you can do things like “give me all the orders of this customer” by writing “foreach Order in Customer.Orders”. The framework will perform the query for you, and life is good, right?
In reality, things are never simple. The generated queries are often more complex and data-heavy than we absolutely need. Also, it becomes super easy to introduce a bunch of extra queries and create humongous loads on the database.
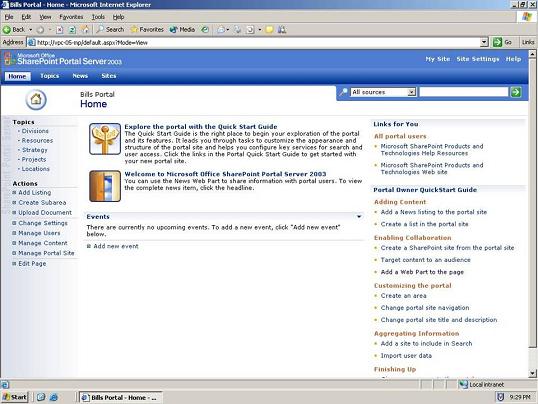
Let’s look at a case study. This is the default homepage of SharePoint Portal 2003. There’s also SharePoint Portal 2007, which looks a little fancier, but this was the project where I personally worked on performance, that’s why it’s included.
Everything you see here is dynamic, the vertical navigation bars, actions on the left, stuff in the lists etc., people can add and edit the elements in all of these.
The data in the various lists, navigation structure etc is all stored in a SQL database.
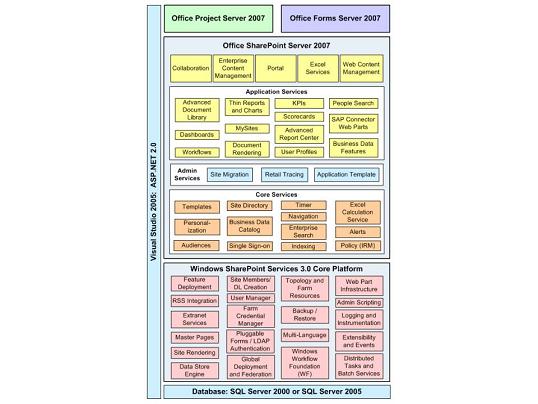
This diagram is from more recent times, showing the architecture of MOSS 2007
The main point I want to illustrate here is that there’s the base product, Windows SharePoint Services, and lots of other product teams build their stuff on top of it, essentially doing custom SharePoint development, just like many independent SharePoint solution builders all over the world.

-SharePoint can be thought of as a special kind of object-relation mapper.
It stores everything in a database
Also exposes an object model that lets people query and manipulate different kinds of data (sites, lists, web parts, documents). The object model generates SQL calls, which perform the actual operations.
In order to perform any sort of interesting operation, say copy some documents from one list to another, people often have to call a bunch of small, simple APIs, but all of them tend to generate one sort of query or another
Throughout times, I’ve had to diagnose and profile various SharePoint installations, and there’s a common theme: The developer says, hey, everything works OK on my machine, and all I have is these simple operations, how can they be slow?
Under stress, application behaves erratically, oftentimes pages load very slowly
When looking at SQL, it’s common to see very high CPU/memory usage, and some individual queries look super slow in SQL profiler, but it’s inconsistent. Another thing that we see is tons and tons of queries bombarding SQL server many times per second. What really happens is that when SQL server gets a bunch of requests, it cannot service them all at once, relevant data will be locked more often, and other queries have to wait etc.
This situation is what I call the “Estonian Customs” (“Eesti Toll”) application model.

- Let me tell you a story about Estonian Customs
- As you might know, I recently moved from the United States to Estonia, and had to bring all my household stuff to the country. And I had to take some papers to Eesti Toll in order to prove that I had been living abroad and was now moving to Estonia and all this stuff is my stuff.
I’m using a moving company, and had a guy from the moving company to advise me on what paperwork to bring with me. He has been doing it for 20 years, and he has no idea of what kind of papers might be asked at any time.
So we go in with a big stack of all kinds of documents, the official goes through it, and then asks: but why don’t you have a paper that shows that your car was insured in the US? Um… Because I had no idea it was required? So I call my US insurance company and ask for the appropriate paper to be faxed over and send it to the customs. But then they ask for another paper. And a few days later they ask for another paper, which causes me to context switch all the time and stresses out myself and the whole system.
Now software applications that just keep querying for data are just like that as well. Whenever a new feature or a new step in some algorithm is added, we add some code that calls an API method, which usually translates into a query.
This results in a lot of chattiness, every web page load generates tens of queries against SQL, which can add up to a lot of stress in multiuser scenarios.
Also, it usually results in a lot of redundancy, as multiple API calls can often return overlapping data, or even exactly the same data.
Overall, we end up with a death by a thousand cuts – no single query is too bad, but at some point we will add the straw that breaks the camel’s back
Now sometimes this approach is OK. If we are simply prototyping, or we know that this particular piece of functionality will never ever have a high load on it, it will be fine. However, it’s also highly dangerous because as soon as someone changes the conditions by adding more users or lifting this functionality to a different area, things will fall apart very quickly.

-Now let’s come back to our SharePoint story – what did the SharePoint org decide to do?
Realizing the query issue, reducing the number of queries became sort of a holy grail
Every query was examined, and we looked into ways of eliminating them.
There are three basic approaches one can take here:
you can see if multiple queries can be combined into one, especially if the data is similar or overlapping
If you have multiple user interface components that consume the same data (for example, multiple web parts), they can issue a joint query, and consume data from the resulting dataset
And the simplest: cache as much data as you can. If the data that you are reading doesn’t actually change more than once a day or even once per hour, chances are that we can use a simple cache for it. Remember: if you ever need to optimize a query, the first question to ask is: do we need this query at all? Eliminating the query is the perfect optimization ![]()
Now obviously you need to think about the different invalidation algorithms etc – does your cache expire after a certain time, is it explicitly invalidated when data changes etc.
In the end, we had a sort of query police who had the right to ask difficult questions from everyone that introduced new database hits.
As an end result, SharePoint Portal Server 2003 had only 2 queries to render its homepage (this is the web page I was showing before). One for reading web part and list information (as this is something that can change in real time and thus cannot be cached – but it was all combined into one query), and one for checking if anything had changed in the navigation structure of the portal (if something had changed, the data would be reloaded, but in 99% of the cases it was just a very simple and cheap query).
In comparison, I have had to consult and troubleshoot many custom SharePoint installations where people have 20-30-40 queries to render a single page, and then they complain that SharePoint doesn’t scale.
Now the caveat here is that this can lead to the Doctor’s Office appliation model

-Whenever I used to go to a doctor in the United States, the procedure usually involved a lot of waiting.
-First, I have to wait in the registration line, they take my data
-then, I have to wait in the waiting room, together with a bunch of other people. Sometimes they have chairs for everybody, sometimes they do not (memory pressure!)
-Then somebody asks me to come in and sit down somewhere, and I wait again
-Then a nurse comes and takes my blood pressure, after which I wait again
Then I finally get to see a doctor
The symptoms here are:
The place is full of people, they are being shunted from one stop to another
At every stage, someone performs one little procedure with them
In software, the symptom is that we have built tons of little caches everywhere, which behave like the lines in a doctor’s office
In case of SharePoint Portal, we cached so much data that it created huge memory usage, which obviously wasn’t good
Data ise copied around from one place in memory to another a lot
Now this is much better than dealing with Eesti Toll, but not quite perfect
But in most cases, this will actually be fine, as long as you’re sensible about what kind of data you are caching
Also, due to the nature of software layering (and remember that our themes is “trap of OOP” – Object-Oriented programming makes it very tempting to create lots of layers), you can end up doing caching in all those different layers, and then you wonder what your process is doing with all these hundreds of megabytes of memory.

-Some of the approaches we took in the SharePoint applications to combat this:
-Cut out data transformations and data staging
-Created very highly optimized data paths for common operations. For example, everything is treated as a list in SharePoint, so built-in list rendering was made as fast as possible
-Essentially, we ended up translating the data directly from SQL to HTML, bypassing all of the object model layers.Obviously, there were downsides:
-Many of these codepaths became super complicated – they were efficient, but difficult to understand and maintain
-also, this approach does not work for custom development. If you are writing your own code on top of SharePoint, you are on your own, and have to do your own micro-optimizations.-But this is what I call the Hansabank application model 
I recently had a very good experience doing my personal business in Hansabank.
Having just moved back to Estonia, I had to arrange a bunch of stuff, from my Teine Pensionisammas to getting new ATM cards.
The teller had all the relevant information about me, she was competent and technologically empowered to perform all the different procedures.
In software, this is the equivalent of processing all the relevant data in one place
There’s minimal data transfer between components, and data is not just copied from one place to another all the time
Obvious downside: this can get very complex and difficult to maintain, so save this approach for performance-critical areas

Try to think what stages and transformations your data has to go through
You have to pick your application model at the start of the project, as it’s extremely difficult to change afterwards. For example, I’ve seen projects that have been finished with the Eesti Toll model. They get deployed, and obviously the performance will be bad. And then they bring me in and ask for a quick solution how to fix the performance, and I have to tell them that guys, you actually have to rewrite tons of stuff about how you are handling your data.
-Remember also that 90% of performance problems are designed in, not coded in. People sometimes think that Oh, I will write this code, and if the performance is bad, I will optimize my code, and fix it – does not work this way!
Never assume any performance characteristics about any technology, any code that you have written, or any code that anybody else in your team has written. If you haven’t measured its performance, chances are it will be bad. So profile your code, see what is taking up the CPU, what is taking up the memory – knowledge is power.
Also, things usually get worse on their own. You can have a pretty well performing piece of code, but once a bunch of people have added bug fixes and extra features to it, it will usually get a lot slower because they are not thinking about it in a holistic manner. So profile early, and profile often.
And remember to think about all aspects of performance, CPU, memory, I/o, network. Your model choice can shift the bottleneck from one place to another, so you want to know where to invest the effort.

Finally, how to improve your understanding:
Investigate the components you are working with, read their source code if possible
If you don’t have the source, profile the components, examine their behavior
Do NOT become the engineer who built a skyscraper out of materials he did not understand (remember the picture on an earlier slide!)


Selle cachemise jutu peale tekib mul alati küsimus – mul on ju opsüsteemi ketta-cache, on andmebaasi shared buffers (või kuidas teda kuskil nimetatakse) ja lõpuks veel rakenduse enda cache. Lõppkokkuvõttes on kõigis neis kolmes samad andmed. Kas annaks cachemist usaldada andmebaasile ja opsüsteemile?
See ongi see arsti juures käimise mudel – andmeid hoitakse igasugustes erinevated cachedes ja kopeeritakse ühest kohast teise. Samas pole need cached siiski ekvivalentsed – on vahe, kas me hoiame asju omaenda protsessis või on nad mõnes teises protsessis või (nagu SharePointil tihti tehakse) eraldi andmebaasiserveris jne.
Aga sellepärast ongi oluline teada, mis teistes komponentides toimub, et me oskaks mõistlikke otsuseid teha.
The undoubtedly leads to better overall performance of your web server. Class Database Optimized
Leidsin sobiva pildi Eesti Tolli käitumise illustreerimiseks, mis küll “Eesti Toll” mudeliga ei haaku, aga haakub sellega, mida Targo ettekande ajal tollist rääkis. Pilt on siin:
http://www.ekspress.ee/thumbs/2008/09/08/l2_8864.jpg
St isegi kaisukarus nähakse hullu kurjategijat. Igaühe enda asi on tõestada, et ta pole kaamel.
Вот оно как даже…а ты как думал
Carry out the following to discover more on nfl jersey before you are left out.
genuine lavonte david jersey http://www.foulire.com/abouts/custom-printed-sublimated-hockey-jerseys/nfl-jerseys-free-shipping-usa/hvivcvff-p-326.html