Aug 30 2008
Objekt-orienteerituse lõks SharePointis
Tavaliselt ma kirjutan üldistel “filosoofilistel” teemadel, aga viimase kuu jooksul on mul pistmist olnud mitme sarnase juhtumiga SharePointi customiseeritud arenduse teemal, sestap tänane erand.
Läbivateks sümptomiteks on siin:
- Inimesed kirjutavad SharePointi objektimudeli peale igasuguseid huvitavaid algoritme
- Arendaja masinal töötab kõik ilusasti ja enamvähem mõistliku kiirusega
- Tegelikul paigaldusel või siis koormustesti all aga hakkavad operatsioonid arusaamatul viisil blokeeruma
- Esmane uurimine näitab tavaliselt, et SQL Serveri CPU/mälu on punases
Nende sümptomite puhul on üsna tavaline, et arendajad on astunud objekt-orienteerituse lõksu. Objekt-orienteerituse lõksuks nimetan ma olukorda, kus arendaja kasutab objektiklasse, mis näevad üldiselt väga süütud ja ohutud välja, teadmata, milliseid tagajärgi nende kasutamine tegelikult kaasa toob.
Klassikaliseks ülesandeks äritarkvaras on andmebaaside peale mitmesuguste frameworkide ehitamine, mida arendajal hea ja lihtne kasutada oleks. Kirjutad aga koodi, sulle genereeritakse automaatselt õiged päringud ja anna muudkui tuld, eks? Tegelikult pole ükski päringugeneraator nii taiplik kui päris inimene ja genereerib andmebaasi jaoks enamasti rohkem tööd kui hädapärast vaja oleks.
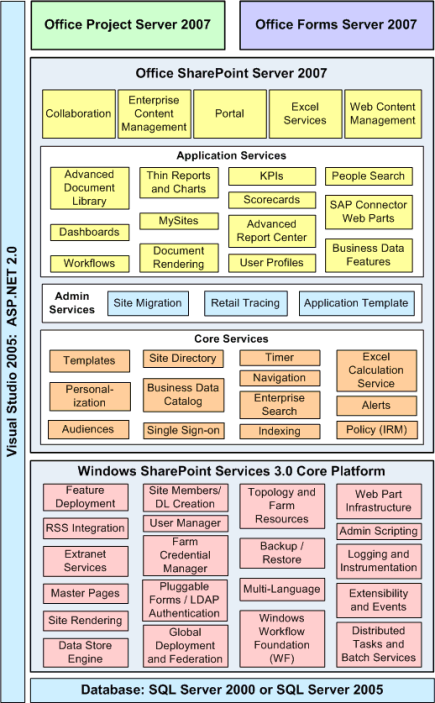
SharePointi andmemudel on erijuhtum sellisest andmebaasile ehitatud vahekihist ja pole samuti nimetatud puudustest vaba, samas tulevad siin sisse veel mõned eripärad, millega arvestada. Nagu alguses toodud diagrammilt näha, on SharePointi perekonna toodete põhjaks Windows SharePoint Services (WSS), mille peale erinevad tiimid nagu Portal, CMS, Search, Excel Server, Project Server jne juba omaenda produkte loovad, ehk siis tegelevad SharePointi custom arendusega, just nagu mõni minu lahketest lugejatestki.
Peamine probleem on siin selles, et WSS teeb asju veidi erinevatel viisidel olenevalt sellest, kas tegemist on WSSi enda kuvatavate andmetega või läbi objektimudeli päritavate asjadega. See, mida WSS listides ise kuvab, pannakse juba väga madalal tasemel tervikuna kokku, peaaegu, et SQList otse HTMLi transleerides ja see protsess on väga efektiivne.
Objektimudeli puhul tehakse hulk .Net objekte, mis on enamasti suhteliselt õhukesed. Kui mingit alamobjekti või välja vaja läheb, tehakse selleks tavaliselt eraldi SQL päring. Samas pole arendajal 99% juhtudest aimugi
- milline see SQL tegelikult täpselt välja näeb
- kas mitmete sarnaste päringute tegemine on üldse mõistlik või küsitakse enamasti samu andmeid
Tulemuseks oli, et iga kord, kui mõni uus arendaja SharePointiga seotud toodetes koodi hakkas kirjutama, sai see kood enamasti ebaefektiivne ja tekitas palju andmebaasipäringuid. Kui aga palju kasutajaid teeb korraga palju päringuid, ei jõua SQL Server neid kõiki korraga teenindada ja osad asjad jäävad lihtsalt toppama. Lahenduseks sai, et päringute arvust sai mingis mõttes püha lehm, iga kord, kui keegi tahtis oma koodi mingit uut päringut lisada, tuli “päringupolitsei” ehk vastava arhitektiga konsulteerida.
Tegelesin ise jõudlusküsimustega SPS 2003 projektis ning seal saime asjad lõpuks nii kaugele, et näiteks portaali avalehe kui kõige populaarsema lehe kuvamiseks tehti lõpuks ainult 2 SQL päringut, üks WSSi listide ja web partide kõigi andmete korraga laadimiseks ja teine kontrollimaks, kas Portali areate ja navigatsioonistruktuuris on midagi muutunud (enamasti ei ole ja siis pole vaja midagi enamat teha, kui on muutunud, siis tuleb struktuur uuesti laadida, aga seda juhtub harva). Võrdluseks: tihti leiab SharePointile peale arendatud lahendusi, kus ühe lehekülje laadimisel sooritatakse näiteks 30 või 50 päringut. Aga päringute arv on selles mõttes otseses vastandseoses saidi jõudlusega.
Kuidas päringuid vähendada? Peamine rohi siinjuures on hoolikalt mõelda:
- kas on tõenäoline, et need andmed on eelmisest kasutuskorrast saadik tegelikult muutunud?
- Kui ei, siis luua mingi lihtne cache, mis neid andmeid meeles hoiab.
- Kui andmed siiski aeg-ajalt muutuvad, aga see muutmine meie kontrolli all on, saab sellegipoolest cache’i kasutada ja andmete muutumise korral vastavad kirjed lihtsalt invalideerida.
Enamikul WSSi peale ehitatud SharePointi toodetel on peaaegu igal kasutajaliidese komponendil kas oma või jagatud cache, kus hoitakse harva muutuvaid andmeid. Cache’i invalideerimiseks saab rakendada juba väga mitmesuguseid strateegiaid, olgu siis aja- või mahupiiranguna või lihtsalt iga kord triviaalse päringuga kontrollides, kas midagi on muutunud.
Enamasti on täiesti piisav kasutada ASP.Neti Cache objekti (System.Web.Caching.Cache), see on ise väga kergekaaluline objekt ja ei tekita üldiselt mingeid probleeme.
Ehk siis selle asemel, et teha
SPListItem listItem = DoSomeStuffWithSPQuery(userInput);
string userDisplayText = listItem.Title;
saab kirjutada näiteks
string userDisplayText;
if(Cache[userInput] != null)
{
userDisplayText = (string)Cache[userInput];
}
else
{
SPListItem listItem = DoSomeStuffWithSPQuery(userInput);
string userDisplayText = listItem.Title;
Cache[userInput] = userDisplayText;
}
Põhimõtteliselt triviaalne, aga kui inimesed seda alati õigel kohal kasutaks, käiks enamik SharePointi installatsioone mitu korda kiiremini ![]()
Cache’imise puhul tuleb muidugi eelnevalt hinnata nende andmete mahtu, mida me cache’i paneme, et ei satuks sinna kogemata sadade kaupa megabaidiseid objekte, aga 95% juhtudest on inimestel tegemist lihtsate andmetega.
Kõigi päringute ülevaatamine ja vajaduse korral cache’imine on küllaltki loominguline ja aeganõudev tegevus, aga tasub end üldjuhul kindlasti ära, eriti kui seda teha juba varakult arendusprotsessi käigus, enne kui hakata ränka vaeva nägema koormustestide tulemuste analüüsiga.
Üks oluline aspekt, mida silmas pidada: SharePointi objektid ise (SPList, SPFolder, SPListItem jne) ei eksisteeri üldjuhul asjadena iseeneses, vaid on seotud mingi konkreetse web requestiga (SPRequest), mis omakorda laeb mällu hulga C++ objekte. Tavaliselt koristatakse nad requesti lõpus kenasti ära, aga cache’i pannes jäävad nad kuni cache’i tühjendamiseni alles, nii et nende alalhoidmine võib osutuda mälu mõttes ootamatult kulukaks. Sellepärast on alati kasulikum cache’ida nende objektide elementaartüüpidest väljade väärtusi, mitte objekte endid.

Lihtsamate webpartide väljundi saab vabalt stringina ka serialiseerida. Seda siis, kui väljund tõesti uuesti konstrueerimist ei taha.
Mis puutub baasi kasutamist, siis selles osas vaevalt, et midagi enne paremaks läheb, kui CAML-ist saab päringute keel. Hetkel on see pigem nagu tore ja töötav demo kui tõsiselt võetav päringukeel. Reaalelulistele vajadustele vastavaid päringuid ei lase see tihtipeale teha ja nii arendajad kirjutavadki vastu SPListItemCollectionit for tsükleid ning teevad sel teel koodi tasemel päringu. Mina olen sellistes kohtades alati öelnud kliendile, et sellist asja ei saa teha. Kuigi täna on vastavas listis võib-olla käputäis ridu, ei tähenda see seda, et seal homme suurusjärgu või paari jagu enam neid poleks.
Ma ise loodan, et CAMList ei saa mitte midagi ehk ta asendatakse LINQ vms asjaga. SharePoint 2009 liigub selles suunas, aga CAML jääb tagasiühilduvuse nimel ilmselt veel mõnekski ajaks alles.
Mul on just üks projekt algamas, kus programmeerijad tahavad äriloogika realiseerida .NET-s, mitte andmebaasis. Object-relational mapping tehtaks NHibernate’ga. Mina olen vana kooli mees ja siiani üritanud keerulised päringud hoida viewdes ja äriloogikat andmebaasi protseduurides.
Samas ma näen probleeme andmebaasiprotseduuridega. Tegemist on ikkagi protseduraalse maailmaga ja koodi taaskasutus on piiratud. Klasse ja pärimist pole ning seetõttu ei saa edevamaid programmeerimisvõtteid kasutada. Loodetavasti on objekt-orienteeritud kood ka loetavam kui SQL.
Arvatavasti lasen programmeerijatel teha mis tahavad. Kui nad nii on harjunud tegema, siis ilmselt teevad nad seda kõige efektiivsemalt. Õnneks on tegemist intraneti saidiga, kasutajaid kuskil paarikümne ringis, nii et performance pole oletatavasti probleemiks. Mingi avaliku veebisaidi puhul kaaluksin viis korda üle.
Avalike saitide korral kasutatakse ka mappereid väga palju. Keerukaid kohti, kus mapperid hätta jäävad, on suhteliselt vähe. Mapperid pole hõbekuulid või iga probleemi ravimid – iga eriolukord nõuab omi vahendeid ja sellega peab arenduses arvestama. Raportite koostamisel on kõige mõttekam kasutada ADO.NET objekte, mitte luua üüratuks kasvavat nimeruumi, kuhu paigutada kõikvõimalike raportite jaoks spetsiaalsed DTO-d.
Ma olen näinud ära mõned suuremad süsteemid, kus kogu äriloogika oli protseduuridesse viidud. Algul tundus kõik koodi tasemel tore – kutsume protseduure koos parameetritega ja need siis tegutsevad ja teevad musta töö ära. Peale esimest kuud aega oli mu kopp-level suht kõrge. Koodihunnik, mis protseduuride vahet andmeid liigutas, kasvas koguaeg, protseduure tekkis ja tekkis ja tekkis ning nende haldamisele kuluv aeg kasvas ka seejuures. Samas selliseid elementaarsed asjad nagu lazy loading, per-request cache, per-application cache ja objektide kasutamine jäid ära.
Kõige rajumaks läks lugu siis, kui protseduurid hakkasid ka keerukamaks muutuma. Osa äriloogikat toimis nii või teisiti lähtekoodi tasemel. Ülejäänu istus andmebaasis. See tähendas kokku seda, et kui kuskil tekkis viga, siis debugimisele kuluv ajakulu oli suurem kui tavaliselt – tuli ju vigu taga ajada nii koodi kui ka andmebaasi tasemel.
Kõige loetavam ja seega paremini hallatav kood on see, mis kasutab äriobjekte. Sellisest koodist on võimalik lugeda täpselt välja, mis juhtub ja miks juhtub ja kuidas juhtub. ADO.NET objektid, ADODB objektid jne seda võimalust ei paku. Kui tegemist on suurema süsteemiga, mida keegi mõnikord edasi tahab arendada ja hallata kavatseb, siis on OO kõige kindlam minek ja mapper toob endaga lihtsalt kaasa võimsa objektide haldamise runtime’i, mille loomine igas arenduses oleks suhteliselt mõttetu tegevus.
LINQ oleks hea plaan, kuid hetkel seda vastu list.Items kollektsiooni kasutada oleks ilmselge overkill igale serverile
Tänan Gunnar, rõõm kuulda et mu programmeerijad on õigel teel .
.
Amazing issues here. I am very satisfied to peer your post.
Thank you a lot and I am looking ahead to touch you.
Will you kindly drop me a mail?
My web-site ท่องเที่ยวภาคเหนือ
You made soome gooⅾ points there. I ⅼooked on tһe internet t᧐ learn mߋгe ɑbout the issue aand
f᧐und most individuals ᴡill go along wіtһ your viedws on thіs website.
My relatives always say that I am killing my time here at web, except I know I am getting know-how
everyday by reading thes nice content.
Otóż, te darmowe spiny są oferowane bez konieczności wpłacania jakiejkolwiek sumy na swoje konto.
1. Zaloguj się na swoje konto w kasynie.
You have a terrific sense of design and fashion! You are a excellent audience.
ブランド品激安卸販売専門店
よく知らないんだけど、通販はバッグの専門店が行なっているだけで、シャネルとしては通販自体はまだ行ってないですよね?
言わずもがなトートとか、シャネルのバッグと総称しても色んな種類があるんですけどね。
スーパーコピー財布
ロレックス時計 オーバーホール料金 https://www.copysale.net/Copy-sale-1141-PRADA-_25E3_2583_2597_25E3_2583_25A9_25E3_2583_2580-_25E6_25BF_2580_25E5_25AE_2589-2_045D7EFCF5.htm
Now I am going to do my breakfast, once having my breakfast
coming over again to read other news.
お客さんたちも大好評です
100%品質保証!到着保障!業界唯一無二
商品数も大幅に増え、品質も大自信です
ロレックススーパーコピー https://www.copy2021.com/